缓存在业务场景中多用于存储数据,避免频繁调用后端数据库服务,减轻数据库压力,提高业务吞吐量;本文是笔者翻译的一篇关于如何保证在业务缓存数据的一致性
—-译文—-
今日Redis已经成为互联网行业最受欢迎的缓存解决方案。尽管关系型数据库系统(SQL)同样带来很多非常棒的特性如ACID,但在高负载场景维持这些特性会导致数据库性能下降。为了解决这类问题,很多公司和网站在应用层和存储层增加缓存层。缓存层通常是基于内存实现。因为事务型数据库的瓶颈通常是磁盘I/O。过去十年内存条价格已经下降很多,可以采用在内存中存储数据提高性能,其中最流行的选择是Redis。
目前,大部分系统都会在内存中存储热数据(hot data)。根据帕累托原则(2/8原则),20%的原因会影响80%结果。基于次原则我们会存储20%的数据在缓存层。为了识别热数据(hot data),我们采用淘汰策略如LRU或LFU算法发现即将过期的数据。
背景
很早之前提过,SQL数据库的数据会存储在内存中如Redis。尽管性能得到提升,这种方法会带来巨大的问题;可信的数据源不再是单一的,相同的数据会存储在两个地方。我们如何能在避免阻塞的同时保证Redis中的数据和数据库中的数据一致性?
我们需要指出这种缓存方案存在的一些问题,我们讨论的问题可以扩展到其他数据库或两个内存层之间的一致性问题
解决方案
下面是我们描述的关于这个问题的一些方法。这些方案大部分是正确的(但是依然存在问题)。换句话说,他们可以在99.9%的时间中保证两个数据层的一致性。然而在强一致性和高流量场景中仍然会出错(缓存层出现脏数据)。
然而这些正确的方案是业界在很多年都在使用,并没有出现严重的问题。有时候提升99.9%的正确性到100%是非常有挑战性的。现实环境中产品快速地开发并且更快地推向市场才是重要的。
Cache Expiry
一些原生的方案尝试使用缓存过期(cache expiry)或者保留策略(retention policy)控制MySQL数据库和Redis之间的数据一致性。尽管设置数据的过期时间
这是一个很好的实践,但在Redis集群中使用保留策略(retention policy)是非常糟糕的。如果把数据的过期时间设置为30min,你确定理解半小时内存在业务会读取到脏数据的风险?
如果设置过期时间更短一点呢?比如设置成1min,不幸的是高并发和高流量场景中会导致业务产生数百万美元的经济损失。
如果设置过期时间更短一点呢?比如设置成5s,你确实缩短了产生不一致的可能性的时间周期。然后你会被大量的缓存未命中和性能下降所打败。
Cache Aside
不可变操作(read)
- 缓存命中:直接从Redis返回数据,不查询MySQL
- 缓存未命中:查询MySQL数据(可以使用读副本提高性能),保存数据到Redis,向客户端返回数据
可变操作(create,update,delete)
- create,update或者delete操作MySQL数据
- 删除Redis中的数据(update数据之前删除缓存,新数据会在下次miss时重新存储到Redis)
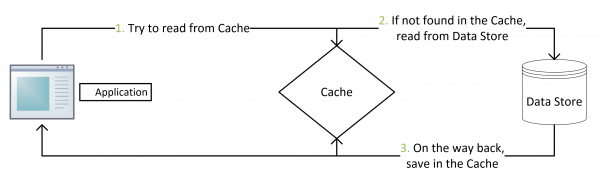
上述方案是目前业务中采用最多的方案。事实上,cache aside方案是实现Redis和MySQL数据一致性的主要方案。Facebook的著名论文Scaling Memcache中也描述过这种方式,然后这种方案依然存在问题。
- 常规场景(指进程不会被kill或MySQL/Redis不会通信失败)
1 | 进程A尝试更新已存在key的缓存值,在某一个时刻,A成功地更新MySQL数据。在进程A删除Redis中数据之前; |
- 极端的解决方案
1 | 相同的业务场景中,如果进程A在尝试删除Redis中旧值之前被kill掉,其他进程依然会读取到这个旧值 |
- 特定场景
1 | 进程C尝试读取Redis中值但没有命中,进程C会查询到MySQL返回的数据。进程C被操作系统挂起一段时间;此刻,进程D尝试更新相同的值,进程D更新MySQL中的数据并且删除Redis中的数据;在这之后,进程C恢复操作将查询到的数据写入Redis中。此刻进程C保存到Redis的数据是脏数据,其他后续进程都会读取到这个脏数据 |
这些操作看起来可怕,但是属于低频率事件
如果进程D尝试更新已存在的值,这个值在进程C读取时就会存在;进程C读取命中的场景就不会发生。如果这个场景出现,缓存值必须已经过期被Redis已经删除掉。
然而这个值如果是热数据(hot data),这个值即使过期,但由于高频次的操作会一直保存在Redis中;如果是冷数据(cold data),会出现弱一致性的情况在一个读请求和一个更新请求同时发生。
事实上,Redis的写操作比MySQL写操作快。操作Redis时,进程C的写操作比进程D的删除操作要快。
场景一
- 不可变操作(read)
- 缓存命中:直接从Redis返回数据,不查询MySQL
- 缓存未命中:从MySQL查询数据,保存到Redis,向客户端返回结果
- 可变操作(create,update,delete)
- 删除Redis中的数据
- create,update或者delete操作MySQL数据
上述算法是比较糟糕的方案。进程A尝试更新已存在的值,在某一个时刻,A进程成功地删除Redis中的数据。在A进程更新MySQL数据之前,进程B尝试从缓存中读取值但未命中,然后进程B查询MySQL中的数据后将数据保存到Redis中。注意此时MySQL中的数据还没有更新。之后进程A更新数据库中的数据后没有再次删除缓存中的值,缓存中的脏数据值会被其他进程读取。
根据上述分析,假设极端情况不会发生,cache aside算法和场景一在一些业务中都不能保证数据的一致性。然而在场景一中使用的操作比原始算法(cache aside)更好点。
场景二
- 不可变操作(read)
- 缓存命中:直接从Redis返回数据,不查询MySQL
- 缓存未命中:从MySQL查询数据,保存到Redis,向客户端返回结果
- 可变操作(create,update,delete)
- create,update或者delete操作MySQL数据
- create,update或者delete操作Redis数据
这种模式也是比较糟糕的方案。现在有两个进程A和进程B尝试更新已存在的值,进程A在进程B之前更新MySQL数据;进程B在进程A之前更新Redis数据;最终MySQL中的数据被进程B更新,Redis中的数据被进程A更新,这会导致数据的不一致性。
Read Through
不可变操作(read)
- 客户端从缓存中读取数据,任何一个缓存命中或未命中都会返回到客户端;如果缓存未命中,Redis自动从数据库中获取数据
可变操作(create,update,delete)
- 这种策略操作,会在
wirte through和write behind模式操作
- 这种策略操作,会在
这种模式的缺陷是很多缓存层都不支持,例如Redis无法直接从MySQL中获取数据保存到自身中(除非使用Redis插件)
Write Through
不可变操作(read)
- 这种模式和
read through模式中操作一致
- 这种模式和
可变操作(create,update,delete)
- 客户端需要在Redis中执行
create,update,delete操作,Redis会通过原子性操作数据同步到MySQL数据库
- 客户端需要在Redis中执行
write through模式的缺陷更加明显,大部分缓存层都不支持这种操作。Redis是被设计成缓存服务,在同步数据到MySQL过程会存在数据丢失。即使Redis支持持久化如RDB和AOF, 也不推荐这种同步数据方案
Write Behind
- 不可变操作(read)
- 这种模式和
read through模式中操作一致
- 这种模式和
- 可变操作(create,update,delete)
- 客户端需要在Redis中执行
create,update,delete操作,Redis会保存数据到消息队列中后直接返回给客户端;通过消息队列更新数据到MySQL
- 客户端需要在Redis中执行
write behind模式和write through模式不同,因为是通过复制数据异步传输到MySQL;消息队列被设计成高可用,这种方式可以提高系统的吞吐量,客户端没必要等待复制数据的过程。Redis Stream模式(Redis 5.0以后版本提供该特性)是一个很好的选择;为了更好的提高性能,可以通过批处理的方式合并MySQL更新操作。
write behind模式的缺陷相似,很多缓存层软件都不支持,消息队列的模式FIFO,更新MySQL数据的操作可能是乱序的,会产生错误结果。
Double Delete
- 不可变操作(read)
- 缓存命中:Redis直接返回数据,不查询MySQL
- 缓存未命中:从MySQL中查询数据,在Redis中保存数据,然后返回给客户端
- 可变操作(create,update,delete)
- 从Redis中删除数据
- 在MySQL中执行
create,update,delete操作 - 执行sleep操作
- 再一次删除Redis中数据
这种方法合并了原生cache aside算法和场景一。是针对cache aside算法的改进。在常规场景中能保证数据的最终一致性。
通过暂停进程500ms操作,这个算法假设所以并发读取进程已经保存Redis中的旧值,第二次删除操作会避免脏数据的发生。尽管一些特殊情况会打破数据的最终一致性,但这种情况是微不足道的。
Write Behind场景
最后,我们提到一个新颖的技术方案如阿里云开发的canal(该项目提供主从模式同步MySQL数据到其他系统)。这种方案可以实现write behind算法,然后需要从其他系统执行复制操作。相比Redis和MySQL之间的数据复制,阿里的这个方案是通过订阅binlog的方式复制数据到Redis,这种方案可以提供更好的可靠性和一致性。binlog是RDMS系统中的一部分,我们可以假设这种方案在灾难环境也是可靠的和具备弹性。这种成熟的架构方案是用来MySQL主从模式的数据复制。
译注:write behind场景需要扩展缓存层功能实现上述算法。
结论
上述讨论的大部分方法可以保证数据的强一致性,但是强一致性方案在Redis和MySQL之间是不现实的。我们通过实现ACID方案保证数据的强一致性。这样做会降低缓存层的性能,这将违背我们使用Redis缓存的目标。
然而所有的方法都尝试达到最终一致性,可能write behind方案(配合canal)是最好的。上面算法是对其他的一些算法改进。为了描述它们的层次结构,绘制了以下树状图。在图中,每个节点通常会比其子节点实现更好的一致性。
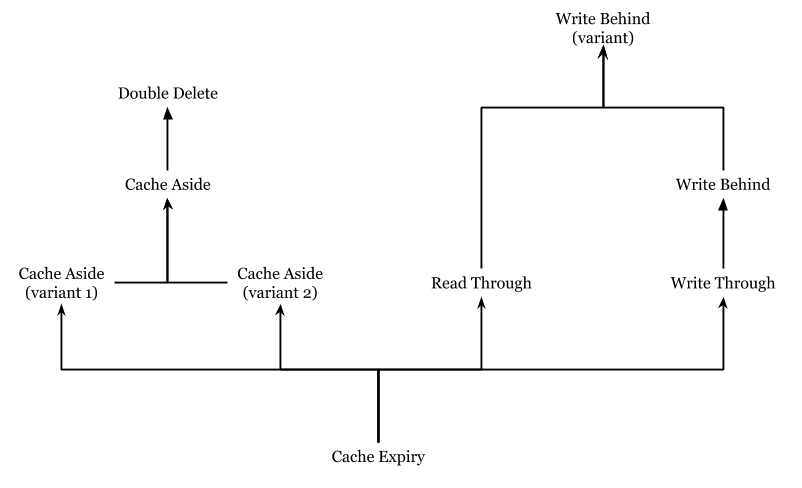
我们得出结论,在100%正确性和性能之间总会有一个权衡。有时候,对于实际用例来说,99.9%的正确率已经足够了。在未来的研究中,我们提醒人们不要违背主题的最初目标。
例如,我们在讨论 MySQL 和 Redis 的一致性时不能牺牲性能。